
Автоматизация бизнеса, делаем процессы эффективными
Собираем лучшие практики и эффективные решения,
которые помогают достигать поставленных целей
- собираем лучшие сервисы и решения для бизнеса
- помогаем с выбором решений
- обеспечиваем техническую поддержку для бизнеса

Подписывайтесь
на Telegram-канал
Обзор сервисов и продуктов для бизнеса,
которые помогают оптимизировать, интегрировать и автоматизировать процессы

Клиенты, маркетинг и продажи →
Увеличивайте продажи, доходы и прибыль. Привлекайте и удерживайте клиентов.

7 идей как привлечь клиентов и увеличить продажи в b2b?
Как увеличить продажи? Как найти больше клиентов? Два ключевых вопроса для многих бизнесов и сегодня попробуем разобрать ряд идей, которые могут помочь с решением.

Интернет реклама: 5 идей для оптимизации
Разбираемся в современных способах повышения эффективности контекстной рекламы. Управление рекламным бюджетом со скидками Вы можете пополнять бюджет рекламных площадок из 1 платформы,…
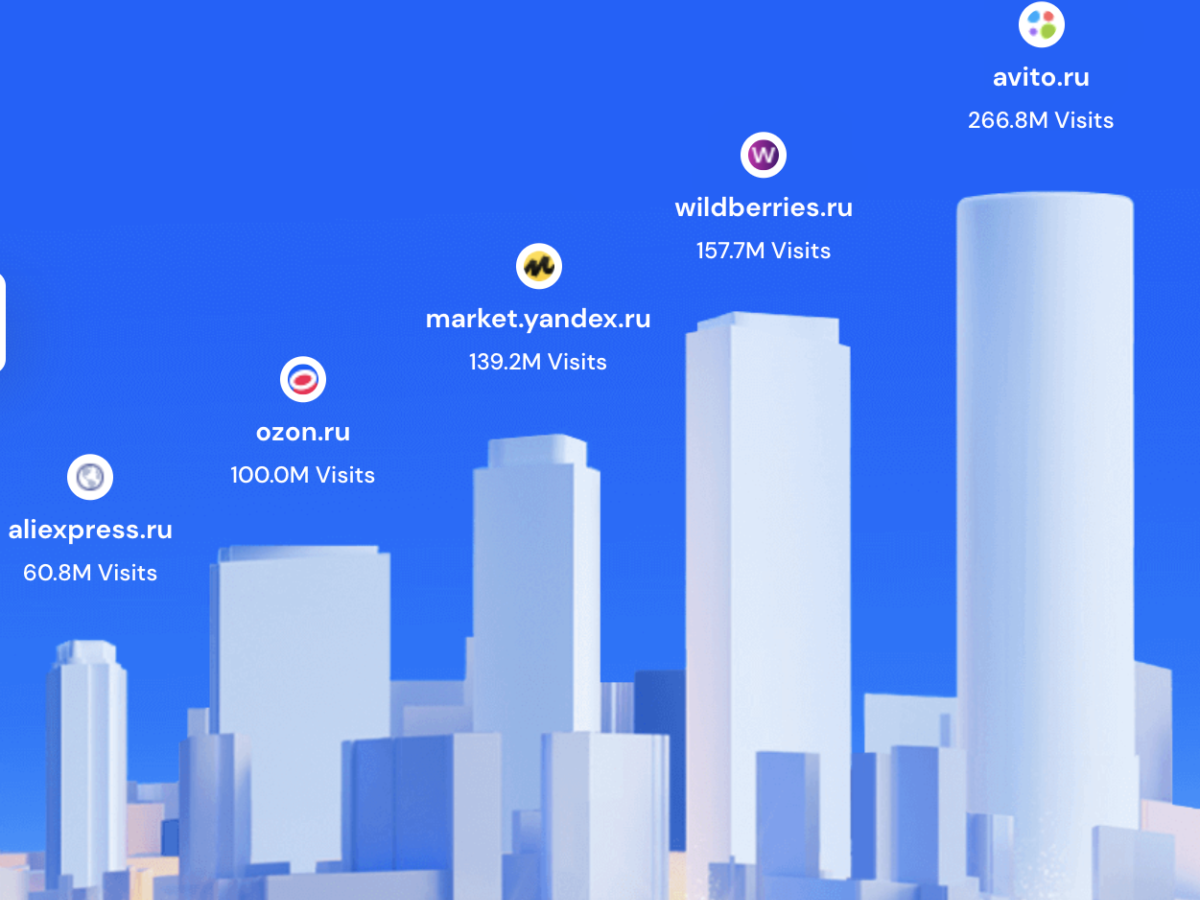
Топ 5 маркетплейсов в РФ по данным Similarweb
В данной статье собрана подборка топ-5 наиболее популярных и значимых маркетплейсов по данным Similarweb на 2021 год в России. В России маркетплейсы…

Лучшие сервисы для автоматизации и оплаты рекламных кабинетов
Сервисы для оптимизации и оплаты рекламы — это онлайн-сервисы, которые позволяют владельцам бизнеса управлять своими рекламными кампаниями в Интернете. Они обеспечивают удобную…

Лучшие бесплатные конструкторы сайтов
В этом обзоре мы рассмотрим лучшие бесплатные конструкторы сайтов для малого бизнеса на основе функций и факторов, которые имеют наибольшее значение, таких…

4P — базовая концепция маркетинга
Рассмотрим 4 базовых акцента маркетинга, который должен знать любой маркетолог. Теория (концепция) 4P (англ. Marketing mix, комплекс маркетинга) — маркетинговая теория, основанная на четырёх основных «координатах» маркетингового планирования: Комплекс…

Процессы, автоматизация и интеграция →
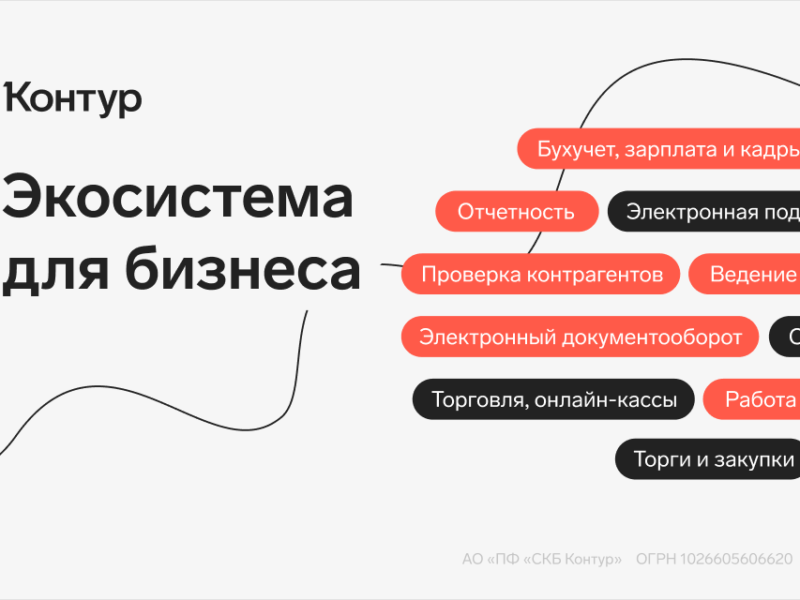
Контур – экосистема для бизнеса
СКБ Контур как экосистему для бизнеса, включает основные сервисы, приложения и продукты для бизнеса. Контур объединяет в себе широкий набор сервисов и продуктов, предназначенных для автоматизации и упрощения рабочих процессов. Он включает в…

14 лучших инструментов для перевода с помощью нейросетей, которые доступны уже сейчас
Как и во многих других сферах жизни, перевод — одна из тех сфер, где искусственный интеллект (ИИ) играет все большую роль. Большинство…

Лучшие платформы для бизнеса, включающих в себя чаты и электронную почту
В наше время электронная почта и чаты являются неотъемлемой частью бизнес-коммуникации. Каждая компания, независимо от масштабов, нуждается в эффективном инструменте для взаимодействия,…

Лучшие сервисы для удаленного доступа в 2024 году
В наше время удаленный доступ к компьютеру стал неотъемлемой частью работы во многих отраслях. Он позволяет сотрудникам компаний работать из любой точки…

Техническое задание и техническое решение + шаблон
Часто возникает проблема между Заказчиками и Разработчиками в понимании друга друга и задачи. Чтобы решить эту проблему обычно Разработчики говорят Заказчику –…

Как ритуал жестов и голосовых команд — Шиса Канко — помогает нам ориентироваться в мире
Поезд подъезжает к станции в Японии. Проводник поезда указывает на платформу, а затем на знаки, указывающие номер поезда и пункт назначения. В…


Финансы, учет и бухгалтерия →

Сервисы для бухгалтерии и автоматизации учета
Самые популярные сервисы для бухгалтерии и автоматизации учета от СКБ Контур.
Системы электронного документооборота для бизнеса
Системы электронного документооборота (ЭДО) становятся все более популярными среди бизнес-сообщества. Они позволяют компаниям сократить время и затраты на обработку документов, повысить качество…

Сервисы для сферы услуг
Самые популярные сервисы для сферы услуг от СКБ Контур.

Онлайн-сервисы для бухгалтеров: подборка популярных решений
Бухгалтерия является одним из самых важных элементов любого бизнеса. Она не только отвечает за учет и контроль финансовых транзакций, но также является…
Сертификат ЭЦП для целей бизнеса: торги, заказы, работа на порталах
Поможем подобрать правильный сертификат для различных сайтов и задач, с учетом специфики вашего бизнеса.

Персонал и кадры →

Сервисы для специалистов по безопасности и охране труда
Самые популярные сервисы для специалистов по безопасности и охране труда от СКБ Контур.

Лучшие онлайн школы по разработке, программированию и диджитал профессиям
Сделали анализ отзывов со всего Интернета и подобрали топ 10 школ, которые реально могут обучать современным профессиям. Обзор и рейтинг с учетом…
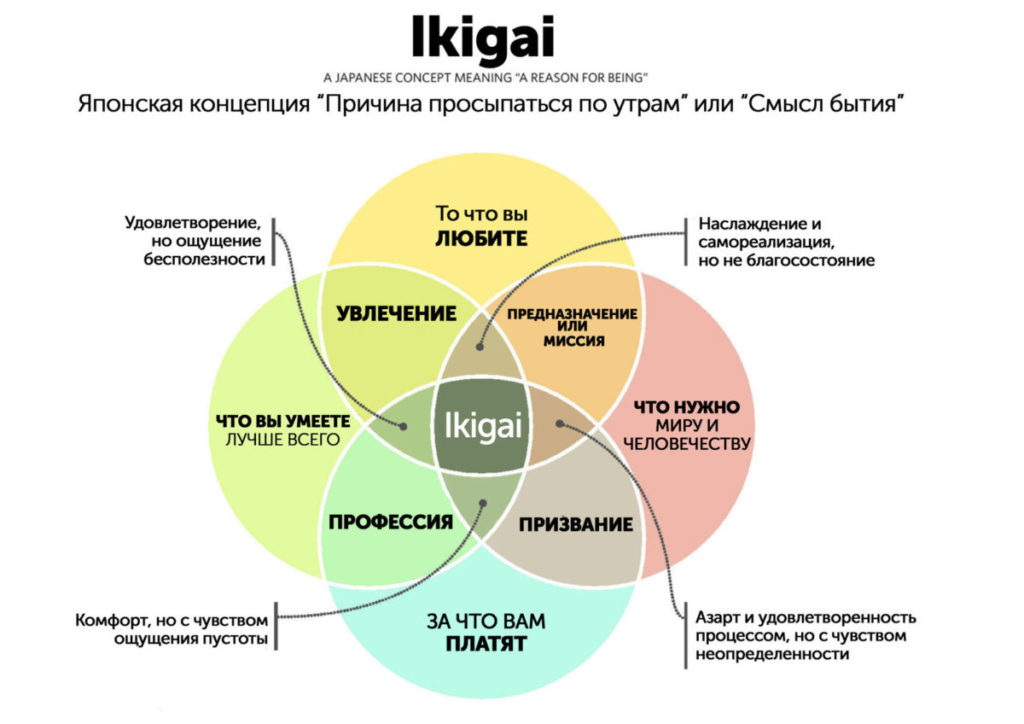
Икигай — осознание своего смысла жизни
В японском языке есть понятие «икигай» — причина, ради которой вы просыпаетесь по утрам. Что такое Икигаи? Икигаи (яп. 生き甲斐 икигаи, «смысл жизни») — японское понятие,…
Эффективность неэффективности — Дорофеев Максим
Про то что компании и команды всегда продают свое узкое горлышко. Загружать людей становится не эффективно. эту статью хорошо дополняет другая:
Skillbox или Skillfactory — Какую школу лучше выбрать?
Какую школу лучше выбрать, Skillbox, Skillfactory, OTUS, Geekbrains или другую для качественного изучения языка? Сегодня IT-сфера востребована как никогда раньше. Десятки онлайн-школ…

Где оформить сертификат ISO в течение 24 часов?
Что представляют собой стандарты ISO? Этапы добровольной сертификации ИСО. Порядок внедрения системы менеджмента на предприятии. Преимущества получения сертификата. Где можно оформить сертификат…




Безопасность
Новый безопасный VPN, на базе технологий TON, Telegram и команды Павла Дурова
Вышел современный безопасный TON VPN на базе Телеграм бота, с оплатой через криптовалюту Toncoin и блокчейн TON. В отличие от множества популярных VPN тут используются проверенные, безопасные и открытые технологии типа WireGuard, OpenVPN…

6 правил кибербезопасности, которыми нужно воспользоваться прямо сейчас
Как научить сотрудников не становиться жертвами обмана злоумышленников в сети? Все…

4 способа защитить вашу работу на удаленке
По данным исследования Gallup, около 42% работников имеют свободный график работы.…

Лучшие VPN для Android
Для обеспечения безопасности при использовании публичных Wi-Fi сетей на Android устройствах,…
Лучшие VPN для YouTube 2023
Ниже приведены 4 VPN сервисов, на которые пользователи могут рассчитывать в…

Как сделать свой VPN в РФ на базе VPS/VDS? За 10 минут, без проблем с блокировкой, на базе Outline VPN
Сегодня множества сайтов заблокированы и чтобы продолжить работу в Интернет нужен…
Личная продуктивность и саморазвитие

Пирамида Грэма — дискуссии, споры, конфликты
Люди любят спорить и участвовать в холиварах. Однако большинство споров легко опускается до очень низкого уровня. И на сколько низко упали участники диалога позволяет понять Пирамида Грэма. Уровень 1. Прямые оскорбления Когда человек оскорбляет вас,…

68 жизненных советов от главного редактора журнала Wired Кевина Келли
Сооснователь и главред журнала Wired, футуролог, автор книг «Новые правила для…

Лучшие приложения для заметок
В наше время хранение информации и заметок играет значительную роль в…

Искусство маленьких шагов
Практика заметного роста результатов и высокой эффективности, когда человек двигается маленькими…
Голодание спасет вашу жизнь — краткий обзор книги
Твое тело наделено удивительной способностью к восстановлению! Расхожий стереотип заключается в…
Лучшие онлайн школы
про IT-разработку и диджитал профессии
Выбираем лучшие платформы для обучения современным профессиям в IT и диджитал
